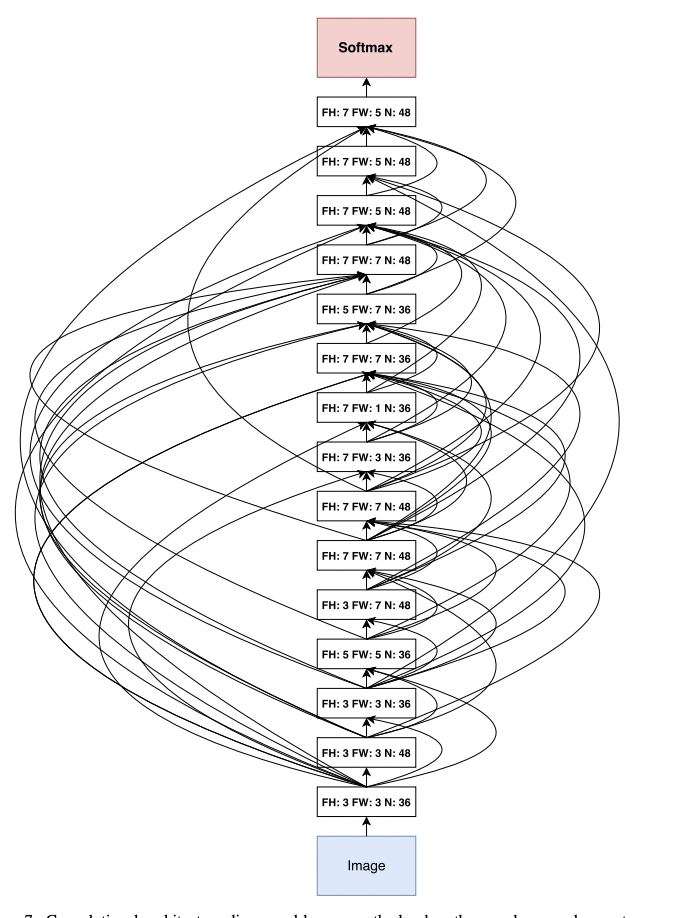
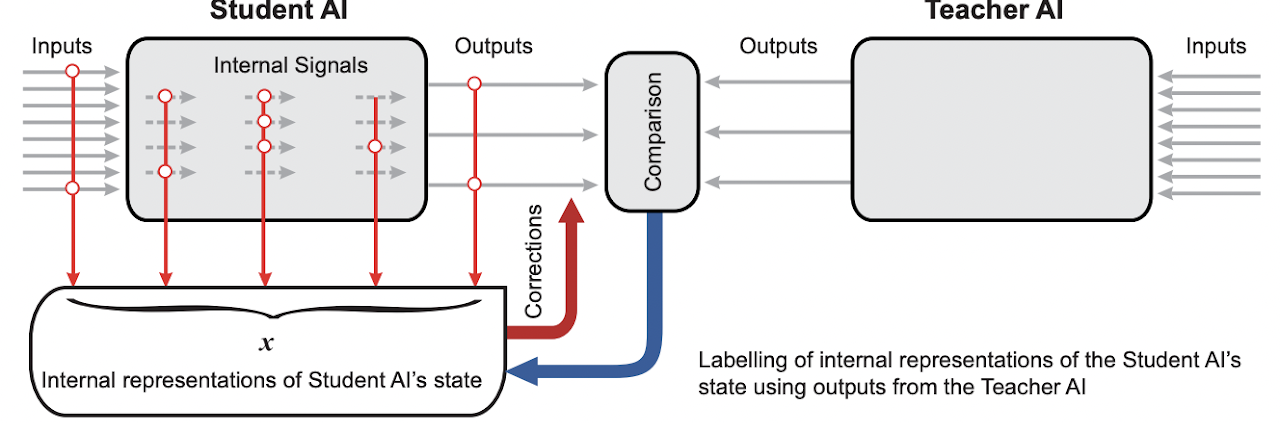
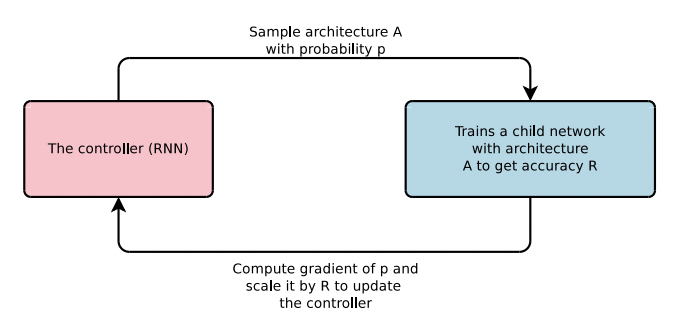
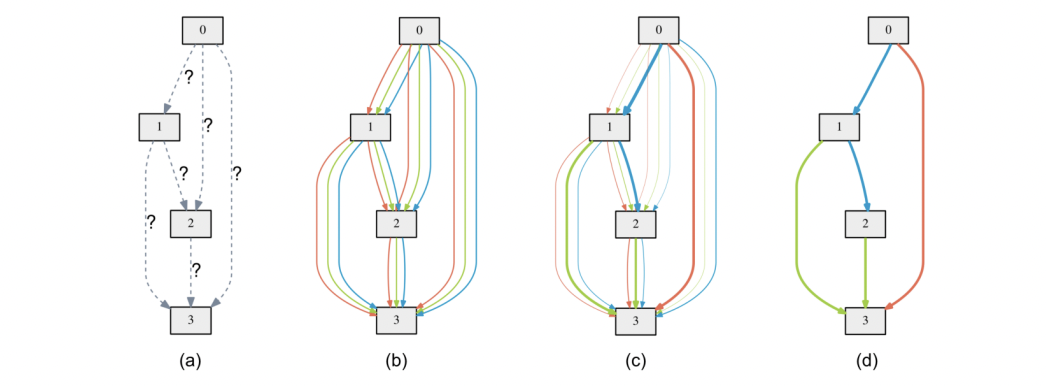
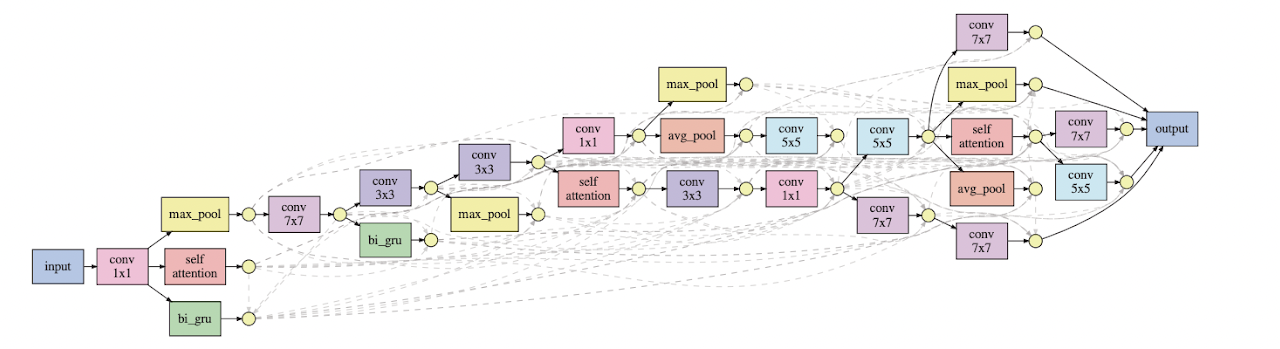
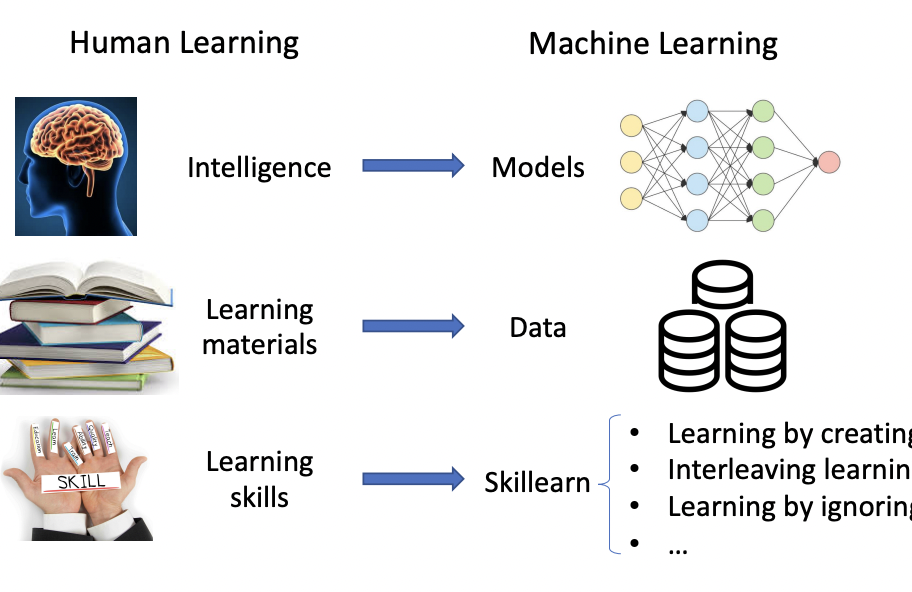
It has been time and professor Pengtao and I started looking at ways to make AI to learn by using methods derived from human learning methods. I wanted to see if we can make neural architecture search on differential architecture use different techniques like teacher student learning, peer based learning, etc. After develpoing the skill learn framework we went forward to explore the concept of evolutionary growth of brain derived from anthropological growths from physical evolution of brain. We wanted to see how AI keeps building AI out of its own accords, chosing different decoders for a task, choosing its own neurons, epochs, activation, inputs, outputs, etc functions and differentiating recursively till it learns the task at hand. Humans learn by interleaving, passing tests or by ignoring! That is what we came forward with and hence, we translated it on machines using mathematics.
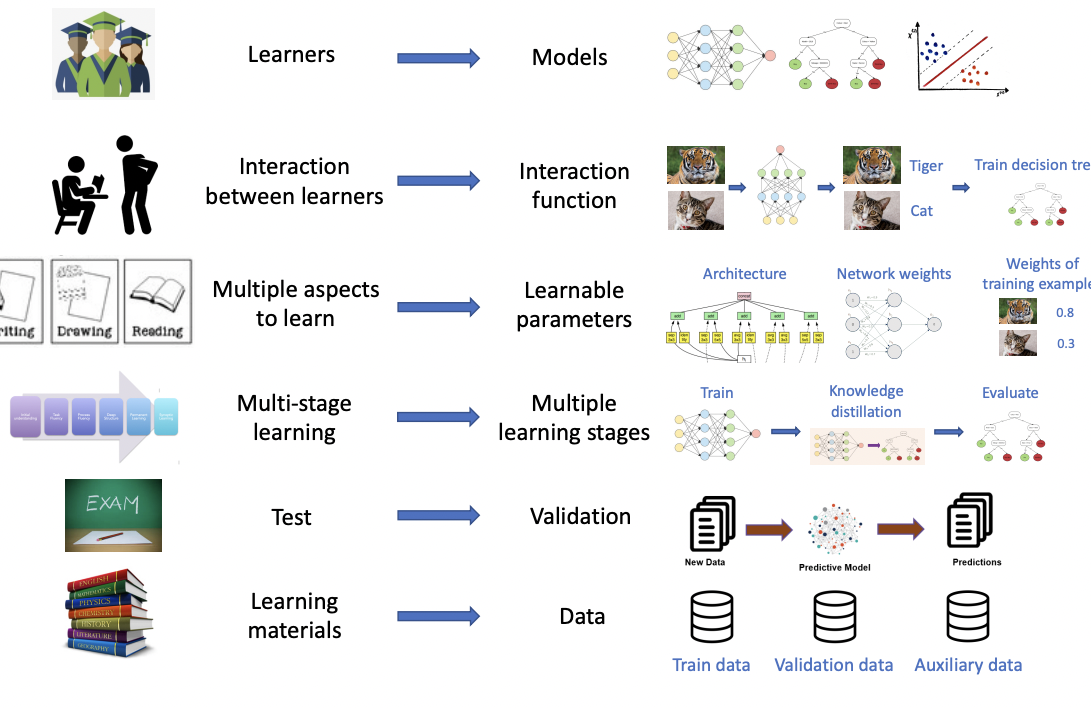
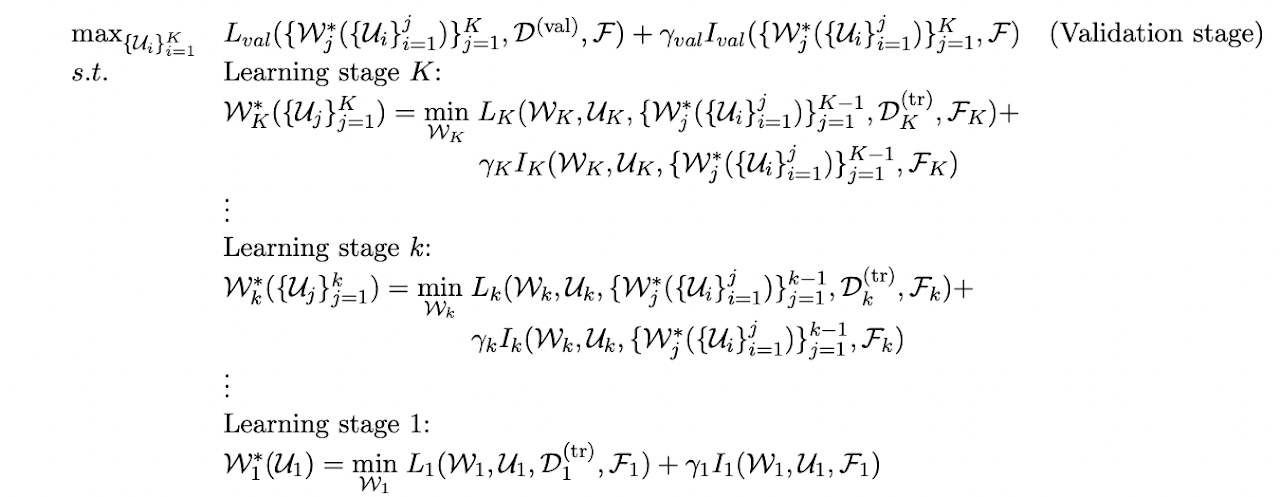
All of the different skills can be translated to mathematical formulae and an algorithm to minimise learners losses recursively. It is a multi-level optimization framework, which involves K + 1 optimization problems. On the constraints are K optimization problems, each corresponding to a learning stage. The K learning stages are ordered. From bottom to top, the optimization problems correspond to the learning stage 1, 2, · · · , K respectively. In the optimization problem of the learning stage k, the optimization variables are the active learnable parameters Wk of all active learners in this stage. The objective function consists of a training loss Lk(Wk, Uk, {W∗ j ({Ui} j i=1)} k−1 j=1 , D (tr) k , Fk) defined on the active learnable parameters Wk, supporting learnable parameters Uk, optimal solutions {W∗ j ({Ui} j i=1)} k−1 j=1 obtained in previous learning stages, active training datasets D (tr) k , and active auxiliary datasets Fk. Typically, Lk(Wk, Uk, {W∗ j ({Ui} j i=1)} k−1 j=1 , D (tr) k , Fk) can be decomposed into a summation of active learners’ individual training losses.